
Sentiment Analysis with Twitter
Introduction
This project was completed for the M.S. - Data Science program through the University of Wisconsin
I live in Salt Lake City, Utah and I love basketball. Basketball has been a major part of my life, both in regards to being a player and a fan. I come from a family of emotional sports fans, and my emotions are very much tied to the outcomes of certain sporting events. For this analysis, I was interested to determine if other Utah Jazz basketball fans are in the same boat as myself. In order to answer this question I turned to Twitter, where people openly post their thoughts to the internet. The hypothesis that I posed is that, if the Jazz lose fans are going to express negative emotions.
Methods
In order to gain insight into this hypothesis, I first needed to gather tweets from Twitter. This was done in Python, utilizing the tweepy library. The tweepy library allows anyone to access Twitter’s API fairly intuitively in Python. Simply put, an API (Appication Programming Interface) allows users/computer to connect with each other and post/get information, essentially passing information. In order to use Twitter’s API, you simply need to log in to Twitter’s developer portal and obtain your access tokens and keys. I stored this information in a .py file on my local machine, and ran the following to set up the API.
import tweepy
import pandas as pd
import nltk
# Download Lexicon for Sentiment Analysis
nltk.download('vader_lexicon')
%run '/filepath/twitter_credentials.py'
#Use tweepy.OAuthHandler to create an authentication using the given key and secret
auth = tweepy.OAuthHandler(consumer_key=con_key, consumer_secret=con_secret)
auth.set_access_token(acc_token, acc_secret)
#Connect to the Twitter API using the authentication
api = tweepy.API(auth)
Due to the fact that, for this project, I was looking at analyzing the difference in emotions for a win vs. a loss, I needed to pull two sets of tweets. The most recent Jazz win when this analysis was completed was December 04, 2018 against the San Antonio Spurs. The most recent Jazz loss was December 02, 2018 against the Miami Heat. In order to find tweets about the team I decided to use four search terms: ‘#utahjazz’, ‘#teamiseverything’(official Utah Jazz hashtag for the 2018-2019 season),‘jazz’, and ‘utah jazz’. The following code represents the functions I built to extract and manage this information.
# Function Definitions
def get_tweets(searchTerms, startSince, endUntil):
"""
Function that returns tweets from Twitter API
searchTerms param = strings that tweets need to contain
startSince param = first date that you want in your tweets
endUntil param = last date you want in your tweets
Returns list of tweets in json format
"""
tweets = []
for tweet in tweepy.Cursor(api.search, q=searchTerms, since=startSince, until=endUntil, tweet_mode='extended').items():
tweets.append(tweet._json)
return tweets
def get_more_tweets(num_needed, searchTerms, startSince, endUntil):
"""
Function derived from get_tweets(), returns more tweets than the 100 limit
num_needed param = Number of tweets that you want to return
searchTerms param = strings that tweets need to contain
startSince param = first date that you want in your tweets
endUntil param = last date you want in your tweets
Returns list of tweets in json format
"""
tweet_list = []
#last_id = -1 # id of last tweet seen
while len(tweet_list) < num_needed:
try:
new_tweets = get_tweets(searchTerms, startSince, endUntil) #api.search(q = '#%23utahjazz', count = 100, max_id = str(last_id - 1))
except tweepy.TweepError as e:
print("Error", e)
break
else:
if not new_tweets:
print("Could not find any more tweets!")
break
tweet_list.extend(new_tweets)
return tweet_list
def extract_tweet_text(tweet_list):
"""
Extract tweet text from list of json tweet objects
"""
tweet_text_list = []
for tweet in tweet_list:
tweet_text_list.append(tweet['full_text'])
return tweet_text_list
def clean_text(text):
# remove puncuation
import string
for p in string.punctuation:
text = text.replace(p, "")
# make lowercase
text = text.lower()
# remove new lines
text = text.replace('\n', ' ')
return(text)
text = (text.encode('ascii', 'ignore')).decode("utf-8")
def nltk_sentiment(tweet):
from nltk.sentiment.vader import SentimentIntensityAnalyzer
nltk_sentiment = SentimentIntensityAnalyzer()
sent_score = nltk_sentiment.polarity_scores(tweet)
return sent_score
# Tweet Collection
# Most recent Jazz win: 2018-12-04
searchTerms = '#%23utahjazz' or '#%23teamiseverything' or 'jazz' or 'utah jazz'
startSinceWin = '2018-12-04'
endUntilWin = '2018-12-05'
win_tweets = get_more_tweets(500, searchTerms, startSinceWin, endUntilWin)
# Most recent Jazz loss: 2018-12-02
startSinceLoss = '2018-12-02'
endUntilLoss = '2018-12-03'
loss_tweets = get_more_tweets(500, searchTerms, startSinceLoss, endUntilLoss)
# Extract text from the json Tweets
win_tweet_text = extract_tweet_text(win_tweets)
loss_tweet_text = extract_tweet_text(loss_tweets)
win_tweet_clean = [clean_text(tweet) for tweet in win_tweet_text]
loss_tweet_clean = [clean_text(tweet) for tweet in loss_tweet_text]
In order to determine if Jazz fans express positive or negative emotions, I needed to conduct a Sentiment Analysis of the tweets I collected. I decided to conduct a simple sentiment analysis using the NLTK library in Python. The most effective way to utilize this library is to have a training set to train the lexicon, but for the purposes of this project I decided to utilize a pre-built sentiment library to analyze each tweet. The output of the analysis is a sentiment score ranging from -1 to 1, with 1 being the most positive and -1 being the most negative.
# Run each tweet in each dataset(win and loss) through the nltk_sentiment function (created in function section)
# Join the results to the original tweets and return the final dataframe
win_sent_results = [nltk_sentiment(tweet) for tweet in win_tweet_clean]
win_results_df = pd.DataFrame(win_sent_results)
win_df = pd.DataFrame(win_tweet_clean, columns = ['tweet'])
win_sent_df = win_df.join(win_results_df)
loss_sent_results = [nltk_sentiment(tweet) for tweet in loss_tweet_clean]
loss_results_df = pd.DataFrame(loss_sent_results)
loss_df = pd.DataFrame(loss_tweet_clean, columns = ['tweet'])
loss_sent_df = loss_df.join(loss_results_df)
Analysis
After determing the sentiment for each of the tweets in both of the samples, I needed to test my hypothesis. In order to test this hypothesis, I decided to use a Welch Two Sample t-test of means - to test the mean sentiment for the tweets after a win and the tweets after a loss. The hypotheses of the test are as follows:
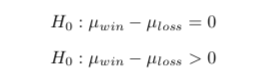
The Null Hypothesis is that the mean sentiment score is the same for the win as the sentiment score for the loss. The Alternative Hypothesis is that the mean sentiment score is higher for the win than the sentiment score for the loss - keep in mind that a higher sentiment score is a positive sentiment. The resulting p-value of the test was 0.8362, meaning that at the α = 0.05 level we do not have sufficient evidence to reject the null hypothesis that the mean sentiment score for wins is greater than the mean sentiment score for losses (with higher sentiment score meaning positive emotions).
Conclusions
After conducting this analysis there are some key takeaways. According to the sentiment scores that I calculated, the emotions appear to be the same for wins and losses. A potential issue with how these scores were calculated is not using a proper training set to train the NLTK lexicon. Another issue could be that these two games could have been not very emotional. In order to truly determine if this is the case for all wins and losses, we would want to to a more robust test over the course of an entire season.